
Lorsqu’on met en place un cluster ElasticSearch, un problème très embêtant peut survenir si on ne configure par correctement le nombre de nœuds « master » dans ce dernier.
Split Brain
Le problème nommé « split brain » se produira plus aisément sur de petits clusters pour lesquels le nombre de nœuds « master » n’a pas correctement été calculé/configuré. Pour notre exemple, prenons un cluster avec deux nœuds répartis sur des sites géographiques différents et contenant chacun un index ElasticSearch constitué d’un shard et d’un replica.
 On peut rencontrer le problème du « split brain » par exemple si une coupure réseau intervient pendant un temps suffisamment long pour que chacun de nos nœuds reçoive une exception ConnectTransportException.
On peut rencontrer le problème du « split brain » par exemple si une coupure réseau intervient pendant un temps suffisamment long pour que chacun de nos nœuds reçoive une exception ConnectTransportException.
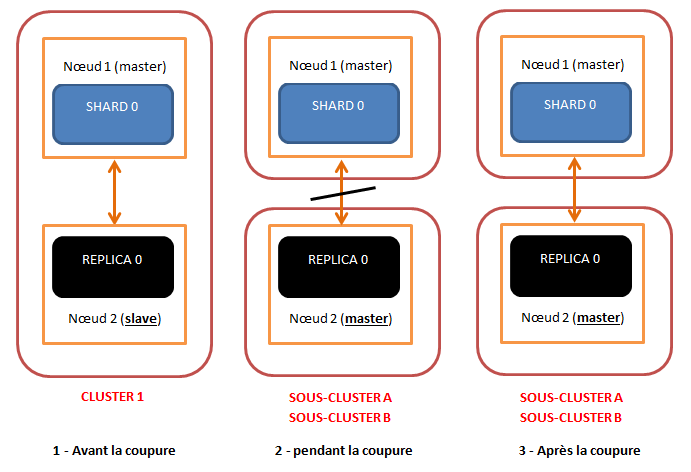
- Pour fonctionner correctement, un cluster Elasticsearch a besoin d’un nœud maître qui détermine où et comment sont répartis les différents shards et réplicas. Le nœud 1 joue ce rôle. Il héberge la partition primaire (shard 0). Le nœud 2 qui est esclave, contient le réplica de la partition du nœud 1. Le réplica est une copie de la partition primaire et peut jouer le rôle de backup en cas de problème sur le nœud 1.
- Une coupure réseau survient entre les 2 nœuds. Lorsqu’il tente de communiquer avec son nœud maître, le nœud 2 reçoit une ConnectTransportException. A plusieurs reprises, toutes les n secondes, le nœud 2 essaie de se reconnecter au cluster. Mais en vain… Possédant un réplica complet de l’index, sans nœud voisin, le nœud 2 va alors s’autoproclamer maître. Deux « sous-clusters » existent alors sur le réseau, chacun étant capable de répondre à des requêtes de recherche et d’indexation de manière totalement indépendante.
- Une fois le réseau correctement rétabli, les 2 nœuds ne se réunissent pas en un seul et même cluster comme on pourrait le prévoir. Deux clusters indépendants coexistent parfaitement. C’est ce que l’on appelle le Split Brain. Cette situation entraîne une divergence progressive des données présentes sur chacun des sous-clusters, parfois les requêtes d’indexation arrivant sur le nœud 1, parfois sur le nœud 2.
La solution à ce problème est parfaitement connue. Il faut fixer le paramètre discovery.zen.minimum_master_node à N/2 + 1 (avec N le nombre de nœuds), soit 2 dans notre cas. Ce paramètre permet de spécifier que l’élection d’un nouveau nœud maître nécessite la majorité absolue. Coupé en deux, un cluster de 2 nœuds comme le notre n’aurait pas pu élire de nouveau maître. Le Nœud 1 se serait mis en attente du rétablissement du réseau. Le cluster aurait perdu sa haute disponibilité : aucun des nœuds n’aurait pu répondre aux requêtes de recherche.
Avec 3 nœuds, l’isolement d’un nœud par rapport aux deux autres aurait permis de conserver un cluster parfaitement fonctionnel grâce à une bonne répartition des shards et réplicas.
Il faut également noter que le troisième nœud peut être configuré pour ne pas stocker de données (paramètre node.data à false). Il jouera alors simplement un rôle d’arbitre.
En paramétrant un nœud avec les configurations suivantes, on peut lui faire jouer un rôle de Load Balancer pour nos requêtes :
node.data : false node.master : false
Une configuration intéressante pourrait être la suivante :
- Un nœud non master et sans data permettant de router les requêtes de recherche vers tous les nœuds contenant des données.
- Un nœud non master et sans data permettant d’indexer des données vers les nœuds contenant des données.
- Une configuration correcte du nombre minimale de nœud master.
Le but est ici de ne pas indexer et rechercher des données en passant par le même nœud. On augmente ainsi sensiblement les performances en répartissant ces actions sur différents nœuds. On profite également de la fonctionnalité de réplication de données pour les obtenir quelques secondes plus tard dans nos requêtes de recherches.
En utilisant une solution de type RabbitMQ on augmentera encore les performances applicatives en indexant les données de manière asynchrone.
Pour finir…
Pensez à l’utilisation du cluster Elasticsearch avec vagrant disponible sur github, pour vos tests ou vos POC : https://github.com/ypereirareis/vagrant-elasticsearch-cluster
Sources
- http://www.technologies-ebusiness.com/solutions/les-problematiques-elasticsearch
- http://blog.trifork.com/2013/10/24/how-to-avoid-the-split-brain-problem-in-elasticsearch/
- http://www.asktoapps.com/why-elasticsearch-makes-two-master-nodes-in-cluster-split-brain-problem/
- http://gibrown.wordpress.com/2014/02/06/scaling-elasticsearch-part-2-indexing/
Bonjour Yannick,
En lisant ton article, j’ai l’impression que tu t’es fortement inspiré de celui que j’ai mis en ligne le 16 décembre 2013 sur le blog http://www.technologies-ebusiness.com/solutions/les-problematiques-elasticsearch
J’y retrouve des paraphrases, mais également des phrases directement copiées/collées :
– « divergence progressive des données présentes sur chacun des sous-clusters »
– « Possédant un réplica complet de l’index, sans nœud voisin, le nœud 2 va alors s’autoproclamer maître »
Je ne suis pas contre le fait que tu reprennes des idées. Par contre, j’aimerais que tu cites tes sources.
Je t’en remercie par avance,
Antoine Rey
Bonjour,
Tu as raison j’ai pris pas mal d’idées de ton article pour lequel j’avais mis la source.
Cependant, j’édite parfois l’article depuis Windows et parfois depuis Linux et chaque fois que je switch, tous les sauts de lignes de mes articles disparaissent et je dois les reprendre.
J’ai ainsi du supprimer la source et même une partie entière de l’article avant de programmer la publication.
Je rectifie ce point immédiatement.
Mes excuses pour cette erreur et merci pour ton article très intéressant dans sa totalité.