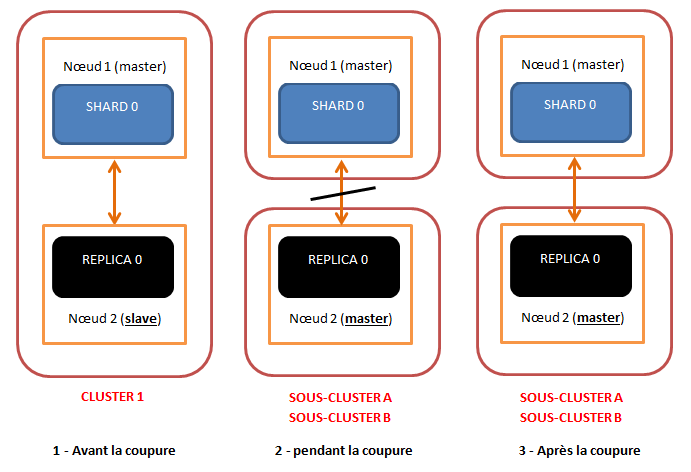
Lorsqu’un cluster ElasticSearch contient plusieurs nœuds, indexes, shards, replicas et surtout des millions, voire des milliards, de documents, il peut parfois être très long de réindexer tout le contenu.
En effet, il peut parfois arriver que l’on ait besoin de changer d’infrastructure technique (machine, virtualisation,…) ou que l’on veuille changer l’architecture du cluster ElasticSearch. Dans ce cas, comment maintenir notre service de recherche opérationnel 24h/24 et 7j/7 (SLA) tout en réalisant les opérations de maintenance désirées (zero downtime) ?
L’utilisation des alias ElasticSearch
Une fois encore les alias vont nous permettre de résoudre notre problématique. Un alias ElasticSearch peut être configuré de manière à pointer vers un ou plusieurs indexes d’un cluster tout en spécifiant des filtres ou des clés de routage.
Le point le plus important réside dans le fait que l’on peut changer la configuration d’un alias en une seule requête vers notre service d’indexation, et ainsi faire pointer un alias vers un ou plusieurs nouveaux indexes que l’on vient de reconstruire ou dont l’architecture vient de changer.
Ainsi, en utilisant systématiquement (bonne pratique) des alias (nom logique) à la place des noms d’indexes (nom physique) dans le code de nos applications clientes des services d’indexation, on pourra très facilement changer le ou les indexes cibles de nos recherches.
Exemple :
L’alias « produits » pointe vers les indexes « produits catégorie A » et « produits catégorie B » depuis que l’instance ElasticSearch a été démarrée. En une seule requête vers le cluster, on peut instantanément faire pointer notre alias « produits » vers les indexes « nouveaux produits catégorie A », « nouveaux produits catégorie B1 » et « nouveaux produits catégorie B2 » et sans interruption de services. On vient de changer par la même occasion notre découpage des indexes.
curl -XPOST localhost:9200/_aliases -d '
{
"actions": [
{ "add": {
"alias": "produits",
"index": "produits_catégorie_A"
}},
{ "add": {
"alias": "produits",
"index": "produits_catégorie_B"
}}
]
}
'
puis
curl -XPOST localhost:9200/_aliases -d '
{
"actions": [
{ "remove": {
"alias": "produits",
"index": "produits_catégorie_A"
}},
{ "remove": {
"alias": "produits",
"index": "produits_catégorie_B"
}},
{ "add": {
"alias": "produits",
"index": "nouveaux_produits_catégorie_A"
}},
{ "add": {
"alias": "produits",
"index": "nouveaux_produits_catégorie_B1"
}},
{ "add": {
"alias": "produits",
"index": "nouveaux_produits_catégorie_B2"
}}
]
}
'
L’alias est la solution à privilégier pour garantir la haute disponibilité d’une application. Les alias permettent également d’organiser logiquement les indexes.
Voici un article sur le blog d’elasticsearch expliquant plus en détail ces problématiques et solutions : http://www.elasticsearch.org/blog/changing-mapping-with-zero-downtime/